Blog
Virtue Ethics, Alignment, Antiqua et Nova
February 12, 2026
I have like an hour to write this up and I am not a Catholic scholar and I have not done a lot of the requisite studying of the canonical alignment texts, so please forgive any minor theological errors and feel free to admonish Claude and I about major ones. But today I wanted to write about the internal consistency of virtue ethics in Catholicism — I’m pretty confident that this can be useful to some people in understanding why Catholics (and potentially Christians) might have certain attitudes to AI development, and I think it could also be useful down the line to guide smarter people in their development of useful alignment tactics.
My Master's thesis, abridged, with thoughts
November 01, 2025
This is a draft. It is incomplete, contains personal notes to myself, and has not been edited for publication. Read at your own risk!
My Master’s thesis, abridged, with thoughts
(Read the full work with citations here. However, I’m happier with the version of my argument presented below.)
I received my Master of Science in Computer Science at UT Austin in August of this past year. I was advised by Risto Miikkulainen as my CS advisor, but was primarily advised by Xue-Xin Wei in the Neuroscience department. I took an extra semester to finish my thesis because I was pretty slow to develop a useful daily structure for myself, and even then I wasn’t completely sure of the story that I wanted to tell with my work until late in the summer semester. I wanted the structure of this program because I didn’t feel like up to that point I had filled my life with things I created and was proud of – now I have this body of work, and it’s pretty messy, but I have achieved some decent level of pride and a good portion of humility to go along with it.
So here’s a very abridged version of my thesis as a little challenge and clarifying exercise to myself, and also so anyone who happens to be curious can engage with it a little easier.
TLDR: my thesis argues that two recent papers, which both present deep neural network models of how the hippocampus forms cognitive maps using place cells, are insufficient in explaining both the form and the function of these cells. Most of the thesis presents an alternate hypothesis for the findings of the first paper; I use the second paper’s findings to support this argument, but ultimately I find that both sets of authors make the same error in their conclusions. This is kind of a mechanistic interpretability project, though the field has disputed boundaries and a lot of names.
First some background. The hippocampus is a small part of the brain that looks like a seahorse – hence the name. It’s mainly known for its central role in consolidating memory (some people might be familiar with patient H.M., who lost his hippocampus and became unable to form any new memories). However, hippocampal recordings of rats exploring familiar environments showed really beautiful response profiles in the hippocampus and the surrounding entorhinal cortex:

Grid cells are really fascinating for a number of reasons, and their discovery won May-Britt Moser, Edvard Moser, and John O’Keefe the Nobel Prize in 2014, but we’re focusing today on place cells which are generally considered to be downstream (I say this with a heavy caveat, the two areas are bidirectionally connected). Place cells are fascinating because they seem to have an endless stream of variants depending on the setting: border cells, head direction cells, object-vector cells, time cells, lap (around a circular track) cells. They seem to care about context: in a task where a rat alternates turning left and right at the same location, some cells will fire for that location only under the context of a right turn, while some prefer the left turn, which implies an “unfolded” latent map of the space. The home of executive function and working memory, the prefrontal cortex, is constantly playing a mirroring game with the hippocampus.
NOTE you say fascinating twice lol
(fig)
I think the thing that excites me the most is that grid cells have been found in humans to be really active during logical reasoning tasks, part of the evidence suggesting that the whole hippocamal-entorhinal circuit is fundamental for organizing conceptual knowledge for rapid inference and generalization. I know every neuroscientist thinks their brain area is the coolest, but I think mine has a pretty good argument, especially within the AI discussion. For this and many other reasons, there are a lot of deep neural network models of this cognitive process, and they illustrate the many debates that neuroscientists have about these cells.
Artificial models in this realm are trained to do a (varyingly) biologically-realistic task, and then the weights and activations are studied to see if they resemble the response profiles of real recorded neurons (in mech interp, this is called concept-based interpretability). There’s a billion of these but I’ll introduce you to three that are most directly related to my work. My advisor’s model from 2018 trains a recurrent neural network to perform path integration: given a stream of velocity and heading direction updates per timestep, predict the currrent (x,y) location. Path integration is the proposed way that animals can keep track of their location across time in the absense of sensory cues, and grid cells are the most popularly hypothesized substrate for this computation (other major works along these lines are Burak and Fiete (2009) and Ganguli et al. (2012)). The trained RNN’s activations are able to explain a wide variety of cell types found in the MEC:
NOTE: I wanna make sure I understand where grid/place cells come from in xx’s paper because I’m saying it’s lacking in the next paragraph. He does NOT get place cells, for the record. HD/border cells are MEC, so say we’ve got a path integrator sort of figured out, but then TEM is nice because predicting the next stimulus provides visual grounding/error correction/helps to explain one way that the HPC/EC circuit could be involved in the sort of general latent space reasoning that it’s purported to be involved in
(xuexin paper figure)
The Tolman-Eichenbaum Machine is another model that’s been a favorite of mine during my program, which influences a lot of my thinking on this topic. TEM is also an RNN-based model, though its model architecture supports a more specific claim: that the content of experiences, and the relationships between those experiences, are two separate inputs which are combined into place cell representations in the hippocampus, explaining their unique range of properties and functions. Specifically, the grid cells in the medial entorhinal cortex use highly processed, indirect sensory information as well as self-motion cues to support non-grounded relations, and the lateral entorhinal cortex supplies more direct and rich sensory information to provide the content. That bit will come back later, but the important part right now is that we now have a model which can accurately predict the sensory specifics associated with each location in its environment.
NOTE: these past two paragraphs are stepping stones. CSCG could come later, or you could tie it in with the fact that we’re modelling place cells by predicting sensory specifics. I also think maybe you could restructure the last paragraph to emphasize that point (that you’re predicting the next observation, which is critical). I’m not gonna write about CSCG right now actually
NOTE: I think you need to discuss anti-aliasing as well, though I wonder if this will come up more naturally later?
So that’s cool, but there’s still two things about the TEM model that can be improved upon: one is that the model relies on allocentric information about its movements, which a biological agent probably wouldn’t have, and another is that TEM only operates over discrete observations, so it doesn’t give a full explanation for how rich sensory information is integrated into a place cell. (NOTE: I don’t love that last bit…could you think of some more examples?) Enter the main model in focus for this thesis: the predictive coding model from Gornet and Thompson (2024). It’s really nice and simple idea: an agent walking around an environment receives a short sequence of visual observations across its trajectory. A ResNet-style encoder turns these images into a sequence of latent features. These latent features go through a few transformer blocks to form predictions for each time step, these predicted latents are decoded with a ResNet decoder to form predicted observations, which are used to train the model via MSE loss in pixel space.
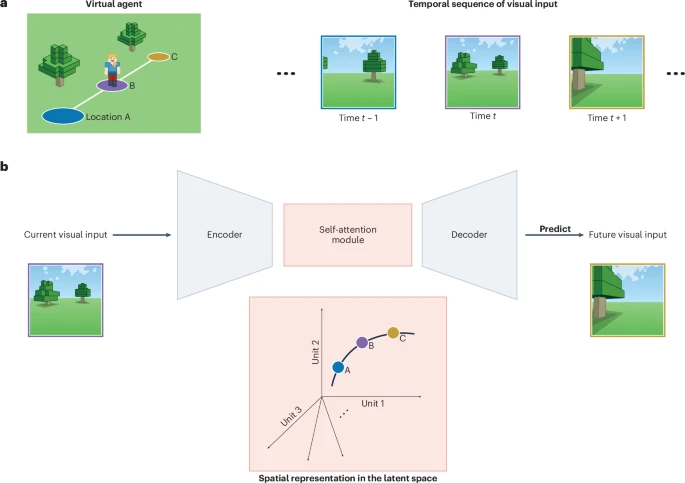
A figure describing their model, which, wouldn’t you know it, comes from a Nature Machine Intelligence News & Views article that my advisor and I wrote to introduce their work. Look, the Minecraft figure is me! It’s short – you can read it here.
(fig from my article, which you should mention in the caption and link)
They motivate this with a nice equation, which makes sense to me.
\[P(I_{k+1} | I_0, I_1, \dots, I_k) = \int_{\Omega} d\mathbf{x} \, P(x_0 \dots x_k) \frac{P(I_0, I_1, \dots, I_k | x_0 \dots x_k)}{P(I_0, I_1, \dots, I_k)} P(x_{k+1} | x_k) P(I_{k+1} | x_{k+1})\] \[= \int_{\Omega} d\mathbf{x} \, P(x_0 \dots x_k | I_0, I_1, \dots, I_k) P(x_{k+1} | x_k) P(I_{k+1} | x_{k+1})\]Under this model, their encoder learns to map observations into locations, the transformer blocks learn to predict realistic movement within the space, and then the decoder learns the inverse mapping between locations and observations. The other two models I mentioned explicitly perform path integration, and then (in the case of TEM) use sensory information to error-correct and ground the model – Gornet and Thomson didn’t really rely on an explicit path-integration system, but it’s an interesting question of if the model is doing this implicitly in order to achieve its high accuracy.
They give two major points in favor of their theory: the PC model’s latent embeddings have more spatial information than a plain autoencoder trained on the same environment (as indicated by the performance of a linear probe), and individual embeddings in the PC model can be reasonably interpreted as place cells (I’ll explain what they mean as reasonable later). This would help to establish that something more “intentional” is going on than just the fact that images are correlated with locations in the environment, and this is where I disagree. I think it’s just image features, and that these image features are not enough to establish a cognitive map.
Let’s discuss the spatial information part first. (I’m using that term casually to refer to the implications of the performance of the linear probe.)
(image showing the spatial info plot, and the SI plot) Linear probes for each model are trained to predict location from latent embeddings. The PC model’s errors tend to be much smaller than the autoencoder’s.
| So this is just a gotcha, but possibly important: if your encoder is learning P(x | I) and outputting a spatial representation x, and your transformer is presumably just transitioning this x to another x, and the evidence for your post-transformer representation being x is that the spatial information is high, shouldn’t the spatial information be high for your pre-transformer x also be high? I didn’t have to perform this test: they show that this isn’t true in their supplementary information. |
(fig from SI) A linear probe from the PC’s latent embeddings pre-prediction recovers similar performance to the autoencoder.
| They present this as evidence that prediction is necessary to form a spatial map, which could still be true, but it does imply that the transformer blocks are instead learning both P(x | I) and P(I_t+1 | I_t). I performed this test at each point in the residual stream and it doesn’t indicate really any differentiation along these lines. (NOTE: is that true? Show a nice figure with all of them overlapping. Take care to see if maybe info develops once and then it’s shifted forward, which might cause a slightly less nice curve or something?) (NOTE: given that my hypothesis is that the transformer is not doing anything special to these image features, I need to explain why the performance is better. I’ve never constructed a perfect argument along this dimension, and I’m happy to admit that some weird map of space is arising here, but (you only need to hedge this if the decoder-swapping thing does fail) my guess is that, for each image “token” in the sequence, the attention + MLP is mixing in information about the image features from surrounding locations, which the linear probe is able to decode a little better. But…maybe that’s just actually how the map is formed!) |
I did a lot of thinking about what would be a good proof that the spatial content in the post-prediction embeddings is not due to them being a code of space. That’s hard! I can , but it’s possible this is a code of space, but it doesn’t work in the way that place cells work, or maybe our understanding of place cells is wrong entirely. I did notice that they train their linear probe only on one image per location, where the agent is facing the same direction. I trained one on a dataset which included multiple viewing angles per location, and saw that the accuracy dropped prodigiously. Maybe there’s some mixed place + head direction encoding going on? Is that normal for hippocampal cells? We’ll come back to that. (basically this whole section can be rewritten when you swap out your decoder)
I did come up with one indirect method for testing what the transformer has actually learned. I extended the predictive coder to include head direction and velocity information, like a path-integrator. Now at every step, the PC receives not only an image, but also the velocity and head direction of the step taken at that location. So in theory the model has everything it needs to predict the next observation perfectly every time. Movement info is embedded with a linear network and concatenated (I tried several variants, this is the only one that works).
Test loss improves with this model, meaning it CAN use this information! However, the trained model is “unsteerable”: you face the model directly north/south/east/west, apply speed, and see if the decoded location matches the movement along whichever axis. So if the model faces north, after a few steps it should show an increase along the Z axis, and it should produce the predicted observations which are expected along this trajectory. I found that it’s unable to do either of these things. You can play with that here: (NOTE: attach colab.)
(attach fig about steering)
NOTE: if you wanna check the first latent token in the sequence, you need to check it in the first part of the residual stream, AND before the MLP right?
NOTE: the fact that the probe trained on all head directions struggles a little kind of goes along with this idea that maybe the transformer is learning some…map of space, but maybe it’s view dependent?
– I want a paragraph here at the end opining on why this is hard in general I think, but keep the rest of it more focused on the actual work that was done
Effortposting
September 28, 2024
Regina George Neel Nanda started a
blog,
so I started a blog. Actually, I’ve been sitting on this for about a year,
threatening to myself to do it every 2 weeks or so, which might be a little bit
more embarrassing.